AI 基础设施
Oracle 助您更快速地在 Oracle 分布式云上运行要求最严苛的 AI 工作负载,包括生成式 AI、计算机视觉和预测性分析。使用 Oracle Cloud Infrastructure (OCI) Supercluster,您可以获得最新 GPU 计算服务并灵活扩展至最高 32768 个 GPU。

为何要选择 OCI AI 基础设施?

出众的 AI 性能和价值
OCI AI 基础设施能够提供极高的 AI 性能和价值,轻松运行所有 AI 工作负载,包括推断、训练和 AI 助手。

最高扩展至 32768 个 GPU
基于裸金属的 OCI Supercluster 具有出色的扩展能力,能够为您加速训练万亿参数 AI 模型。

支持主权 AI
Oracle 的分布式云技术支持您在任意位置部署 AI 基础设施,满足您独特的性能、安全性和 AI 主权要求。
AI 基础设施产品
无论是执行推断、微调还是训练大型横向扩展的生成式 AI 模型,OCI 都能提供出色的裸金属和虚拟机 GPU 集群,通过超高带宽网络和高性能存储满足您的 AI 需求。
-
GPU 实例
基于 A10、GH200* 以及 GB200* NVIDIA GPU 的裸金属和虚拟机适用于推断、微调和小型 AI 模型训练工作负载。
-
Supercluster GPU 实例
基于 A100、H100、H200* 和 B200* NVIDIA GPU 的裸金属计算服务可加速运行万亿参数 AI 模型训练工作负载。
-
集群网络
基于专用集群网络的 RDMA 支持微秒级延迟和 1.6Tb/秒的节点间带宽,能够驱动 AI 基础设施高效运行。
-
高性能存储
面向 AI 基础设施的存储服务不仅包括适用于严苛 AI 工作负载的本地连接 NVMe 存储,还包括 BeeGFS、Lustre 和 WEKA 等集群文件系统。
* 即将推出
众多 AI 创新先行者使用 OCI 来托管、训练和推断新一代 AI 模型。
了解面向大规模 AI 训练的 OCI Supercluster
概述
OCI Supercluster 支持您为单个集群部署最多 32768 个 GPU,充分利用 RDMA 集群网络和本地存储来快速运行大型 AI 模型训练和推断工作负载。
Supercluster 存储服务
OCI Supercluster 支持您访问本地存储、块存储、对象存储和文件存储来执行百亿亿级计算。相比其他主流云技术提供商,OCI 提供更高的高性能本地 NVMe 存储容量,可满足更高频次的训练中检查点要求,进而加快故障恢复速度。
同时,您还可以使用 HPC 文件系统(包括 BeeGFS、GlusterFS、Lustre 和 WEKA)进行规模化 AI 训练而无需担心性能下降。
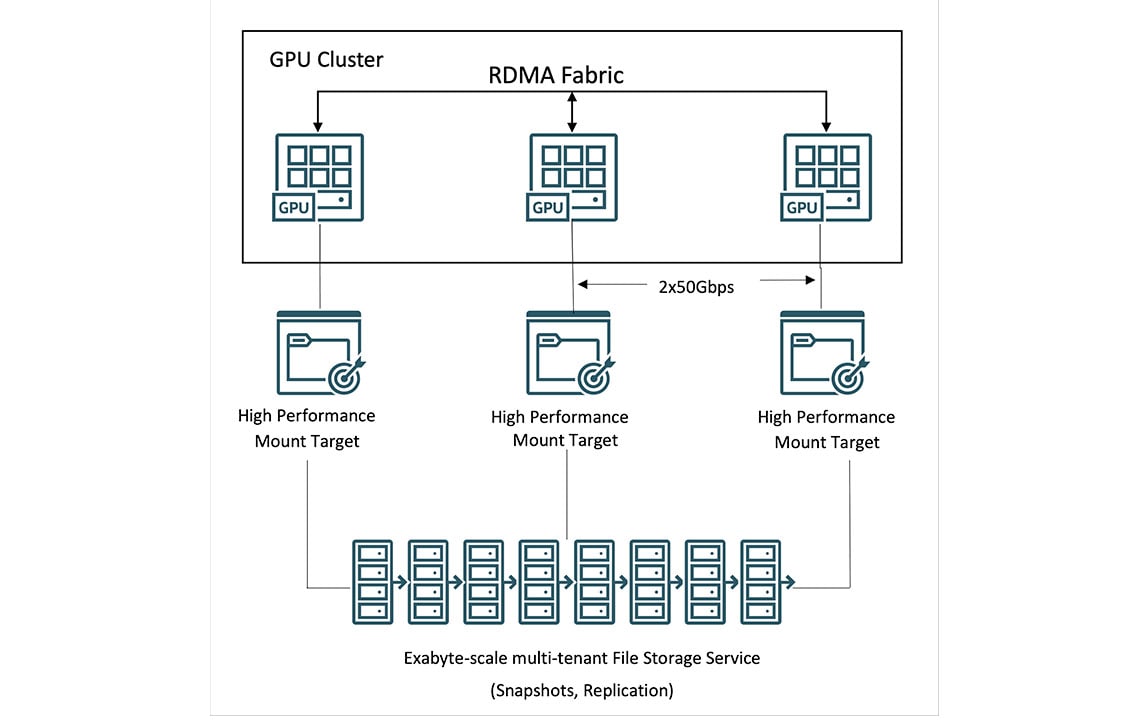
Supercluster 网络服务
基于 Mellanox ConnectX-5 100 Gb/秒网络接口卡和 RoCE v2(基于融合以太网的 RDMA)的高速 RDMA 集群网络支持您创建大型 GPU 实例集群,获得与本地部署环境下相同的超低网络延迟和应用可扩展性优势。
您无需为 RDMA 容量、块存储或网络带宽额外付费,同时前 10 TB 数据出站也完全免费。
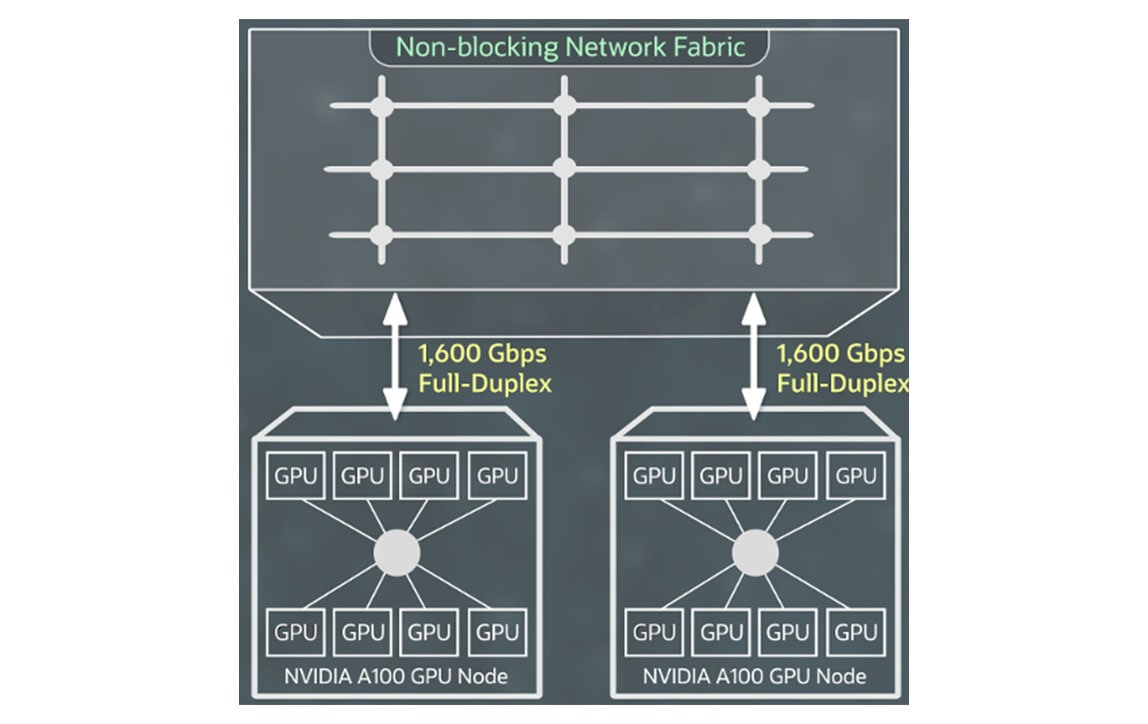
放大+
Supercluster 计算服务
基于 NVIDIA H100 和 A100 GPU 的 OCI 裸金属实例支持您高效运行大型 AI 模型,例如深度学习、会话式 AI 和生成式 AI。使用 OCI Supercluster,您可以将一个集群扩展至最多 32768 个 A100 GPU。
AI 基础设施的典型使用场景
使用基于 GPU 的 OCI 裸金属实例以及 RDMA 集群网络和 OCI Data Science 训练 AI 模型。

使用增强型 AI 工具分析海量历史客户数据对于确保每天数十亿笔金融交易安全至关重要。借助基于 NVIDIA GPU 的 OCI Compute 以及 OCI Data Science 等模型管理工具和其它开源模型,金融机构可以显著降低欺诈风险。

AI 常常被医院用于分析各种类型的医疗图像,例如 X 射线和 MRI 图像。经过良好训练的 AI 模型有助于高效识别需要放射科医生即刻审阅的高优先级图像并向其他人报告最终结果。

药物发现过程既耗时(可能长达数年)又耗费资金(可能耗资数百万美元)。AI 基础设施和分析可以帮助研究人员加快药物发现速度。此外,基于 NVIDIA GPU 的 OCI Compute 以及 AI 工作流管理工具(例如 BioNemo)还能帮助客户管理和预处理自己的数据。

AI 基础设施客户成功案例












赶快行动
试用 Oracle AI 并获得 30 天试用期
Oracle 为大多数 AI 服务提供免费定价套餐,您还可以通过免费试用账户内的 300 美元储值来试用其它云技术服务。Oracle AI 是一个包括生成式 AI 在内的服务组合,它提供预构建机器学习模型,可帮助开发人员更轻松地将 AI 应用到应用和业务运营。
-
哪些 Oracle AI 和 ML 服务提供免费定价层?
- OCI Speech
- OCI Language
- OCI Vision
- OCI Document Understanding
- Machine Learning in Oracle Database
- OCI Data Labeling
您只需为 OCI Data Science 支付计算和存储费用。
更多资源
详细了解 RDMA 集群网络、GPU 实例和裸金属服务器等等。
体验不同之处
- 1/4 出站带宽成本
- 3 倍计算性价比
- 全球统一超低价格
- 无长期承诺的低定价
-
专家能为您解答以下问题:
- 如何开始使用 Oracle Cloud?
- 可以在 OCI 上运行哪些 AI 工作负载?
- OCI 提供哪些类型的 AI 服务?
注:为免疑义,本网页所用以下术语专指以下含义:
- 除Oracle隐私政策外,本网站中提及的“Oracle”专指Oracle境外公司而非甲骨文中国 。
- 相关Cloud或云术语均指代Oracle境外公司提供的云技术或其解决方案。